
Posts tagged Artificial intelligence
The future of (public) transport
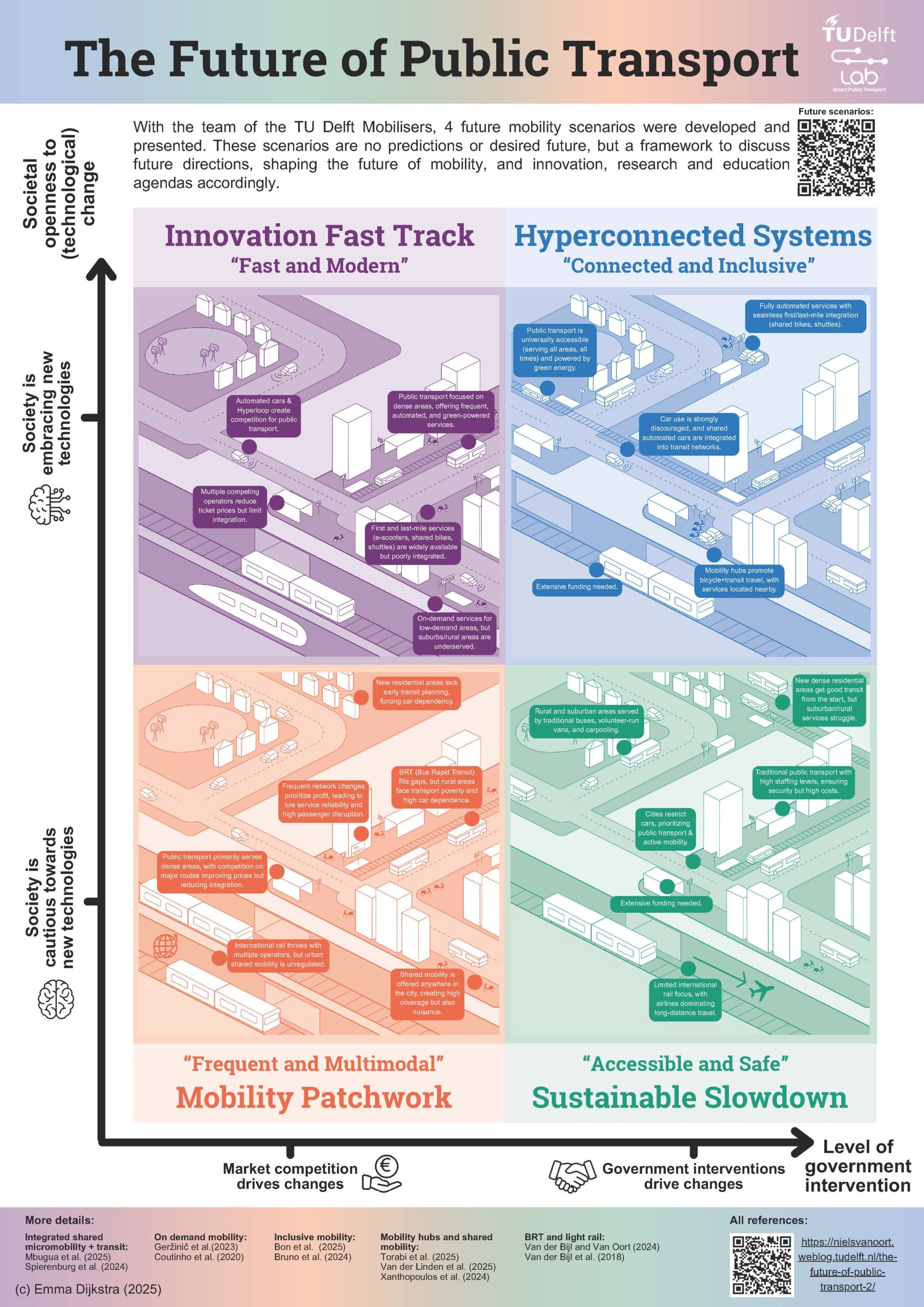
With the team of the TU Delft Mobilisers, we developed 4 future mobility scenarios. These scenarios are no predictions or desired future, but a framework to discuss future directions, shaping the future of mobility, and innovation, research and education agendas accordingly. Find the report HERE.
In addition to the general scenario description, the 12 Mobilisers, from 6 faculties, also wrote perspectives on their own domains. Read my perspectives on public transport and shared mobility HERE or in the infographic. Sources are accessible via the links below the figure.
Relevant research papers/books:
Integrated shared micromobility+transit
Mbugua, W., D. Duives, J.A. Annema, N. van Oort (2025), Societal costs and benefits analysis of integrating bike-sharing systems with public transport: A case study of the public transport bike (‘OV-fiets’) in the Netherlands, Case studies on transport policy.
Spierenburg, L., H. van Lint, N. van Oort (2024), Synergizing cycling and transit: Strategic placement of cycling infrastructure to enhance job accessibility, Journal of Transport Geography, Volume 116.
On demand mobility
Geržinič, N., O. Cats, N. van Oort, S. Hoogendoorn-Lanser & S.P Hoogendoorn (2023) What is the market potential for on-demand services as a train station access mode?, Transportmetrica A: Transport Science.
Coutinho, F.M., van Oort, N., Christoforou, Z., Alonso-González, M.J., Cats, O., Hoogendoorn, S.(2020), Impacts of replacing a fixed public transport line by a demand responsive transport system: Case study of a rural area in Amsterdam, Research in Transportation Economics, art. no. 100910.
Inclusive mobility
Bon, T., M. Bruno, N. van Oort (2025), Three-dimensional transport poverty and its socio-demographic and urban density predictors: Spatial regression analyses of neighborhoods in the Amsterdam metropolitan area, Transportation Research Interdisciplinary Perspectives, Volume 29.
Bruno, M., Kouwenberg, M., & van Oort, N. (2024). Evaluating How Transportation Policy Addresses Transport Related Social Exclusion: A Novel Method Applied to the Amsterdam Transport Region. Transportation Research Interdisciplinary Perspectives, Volume 26
Mobility hubs and shared mobility
Torabi, F., Y. Araghi, N. van Oort, S.P. Hoogendoorn (2025), A latent class approach to explore shared mobility among older people in Midsized Dutch inner cities, Transportation Research Interdisciplinary Perspectives, Volume 33.
Van der Linden, H., G. Correia, N. van Oort, S. Koster, M. Legêne, M. Kroesen (2025), Driving factors behind station-based car sharing adoption: Discovering distinct user profiles through a latent class cluster analysis, Transport Policy, Volume 162, P. 232-241.
Xanthopoulos, S., M. van der Tuin, S. Sharif Azadeh, G. Correia, N. van Oort, M. Snelder (2024), Optimization of the location and capacity of shared multimodal mobility hubs to maximize travel utility in urban areas, Transportation Research Part A: Policy and Practice, Volume 179.
BRT and light rail
Van der Bijl, R. and N. van Oort (2024), Betere Bus, Acquire Publishing
Van der Bijl, R., N. van Oort, B. Bukman (2018), Light Rail Transit Systems: 61 Lessons in Sustainable Urban Development, Elsevier.
Find more research (results) related to key concepts that play a role in (some of) these scenarios:
Onderzoeksagenda / Research agenda
In het openbaar vervoer is nog maar weinig bij het oude. Ontwikkelingen als elektrificatie, automatisering en deelmobiliteit hebben hun impact op vraag én
aanbod. Behalve vlot en veilig moet het ov ook groen en inclusief zijn. En dan is er de nog altijd voelbare impact van covid-19. Om op dit speelveld de juiste keuzes te maken, heeft het ov nieuwe inzichten en nieuwe tools nodig. Zie hiervoor mijn (geactualiseerde) Onderzoeksagenda.
The world of public transport is changing rapidly. Developments such as electrification, automation, and shared mobility have had an impact on both demand and supply. Besides being smooth and safe, public transport must now also be green and inclusive. And then there is the still tangible impact of Covid‑19. To make the right choices in this evolving landscape, we need new knowledge and new tools. Find my (updated) Research Agenda.
Forecasting bus ridership with trip planner usage data: a machine learning application
Currently, public transport gives much attention to environmental impact, costs and traveler satisfaction. Good short-term demand forecasting models can help improve these performance indicators. It can help prevent denied boarding and overcrowding in busses by detecting insufficient capacity beforehand. It could be used to operate more economically by decreasing the frequency or the size of the bus if there is overcapacity. Moreover, it could help operators plan their busses during incidental occasions like big public events where little information is known. Finally, it could be used to reliably inform the travelers on the current crowdedness.
This study investigates the usefulness of a new data source; the usage data of a trip planner. In the Netherlands there are multiple trip planners available for users to help find the most optimal (multimodal) journeys. These trip planners require a date, a time and an origin and destination, which they use to construct multiple alternative journeys from which the user can choose. For this study the data of 9292 was used, being the major trip planner in the Netherlands including all public transport modes.
We developed a model for forecasting the number of people boarding and a model for forecasting the number of people alighting at a certain stop. These forecasts are defined at the vehicle-stop level. By summing the number of people boarding and subtracting the number of people alighting along the trip the forecasted number of passengers after a stop is calculated.
We compare five different machine learning models: multiple linear regression, decision tree, random forests, neural networks and support vector regression with a radial basis kernel. We compare these models with two simple rules: 1 predict the same number as last week, and 2 predict the historic average as number. The models are implemented in the Scikit-Learn library of Python. The data is stored in a PostgresSQL database.
The trip planner datasets and smart card dataset are merged and preprocessed. The resulted dataset is rather sparse; a lot of stops have zero passengers boarding or alighting or requests suggesting to do so. Therefore we investigated if subsampling is needed. From the datasets useful data is selected and features are constructed. The features are standardized. Different number of features are tested, these features are selected based on recursive elimination using a simple random forests model. Finally, the hyperparameters of the models are tuned and the optimal configurations are stored. The scores are validated by using cross validation.
Find more details in the following contributions by Jop van Roosmalen: Transit Data workshop presentation and MSc thesis
Supervised learning: Predicting passenger load in public transport
For many Public Transport (PT) users, overcrowding in PT vehicles has a major decreasing effect on the comfort experience. However, most online routing applications still not take comfort regarding to crowdedness into account, but provide recommendations based on shortest distance, shortest travel-time, or number of interchanges.
Being able to include certain information on crowdedness, requires knowledge about the current and future level of passenger load. Increasing amount and complexity of data describing public transport services allows us to better explore the detection methods and analysis of different phenomena of PT operations. Some countries or operators provide the possibility to use Smart Card (SC) data for occupancy prediction. However, SC data is not available in real time, which makes it hard to incorporate it into real time recommendation models. In this work, we show that it is possible to predict the passenger load via supervised learning, eliminating the need for fare collection data beyond the set needed for training.
Find the CASPT presentation by Léonie Heydenrijk-Ottens HERE